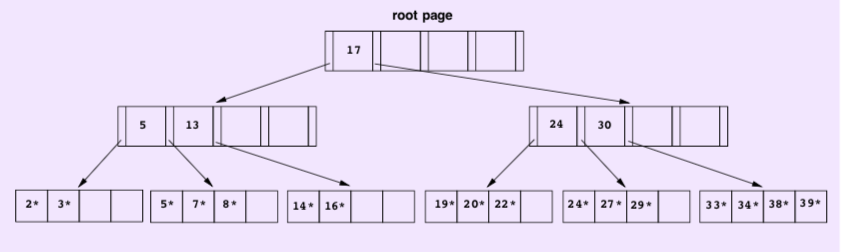
How could we search the query in a certain range?1
2
3SELECT *
FROM CUSTOMERS
WHERE ZIPCODE BETWEEN 8880 AND 8999
We could
- sort the table on disk(in ZIPCODE order)
- use binary search to find the
8880, then sequential scan until ZIPCODE < 8999
We need to read log(#tuple) tuples during the binary search phase. Once we find the lower range limit, we start sequential scan until the upper limit. If the range is huge, the initial binary search can be quite expensive, since the cost is proportional to the number of pages fetched.
In this article we introduce two index data structures, called ISAM and B+ tree. These structures provide efficient support for range selection, insertion and deletion. They also support for equality selections, although they are not as efficient as hash-based indexes.
Indexed Sequential Access Method(ISAM)
We use the index file, its structures is as following. Pairs of the form entry. Key is the minimal value on the page that pointer points to.
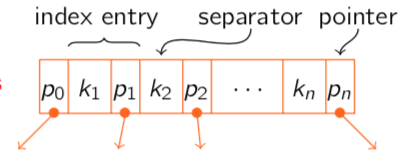
Note that each index file contains more entries and each key serves as a sperator for the content of the pages pointed to by the pointer to its left and right.
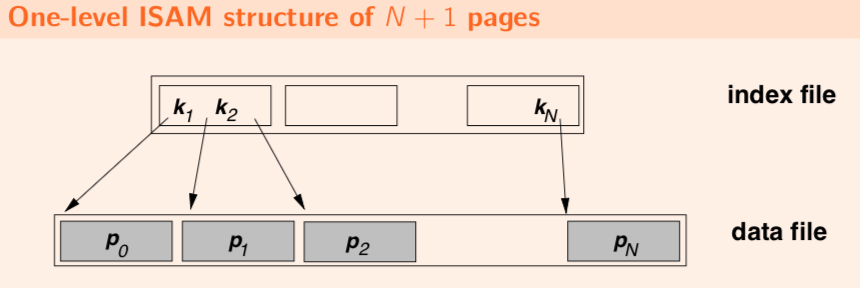
One-level ISAM structure
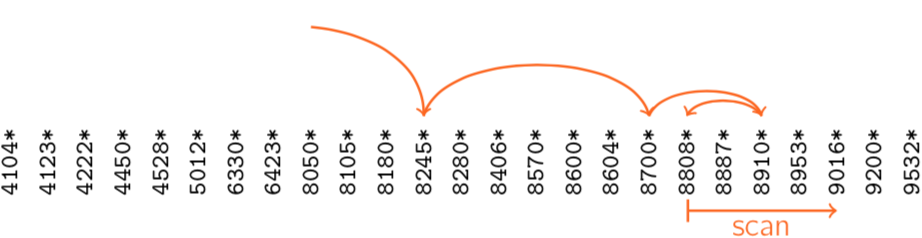
To support range selection, we search on the index file for a key of lower limit. Then we start a sequential scan of the data file from the page pointed to by the entry pointer.
It’s faster searching on the index file then on the data file, because the size of the index file is much more smaller then the data file size.
Multi-level ISAM structure
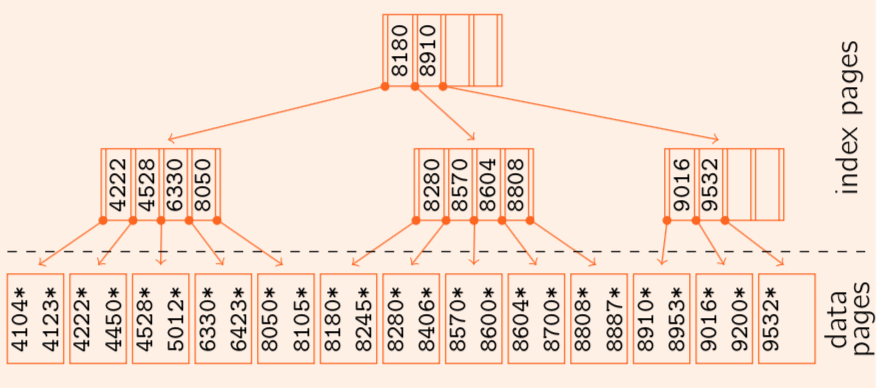
If we want to insert some records into database, overflow pages might be created in order to insert data into. The ISAM tree remains static, so insertions and deletions in the data file do not affect the tree layers.
If a new record is going to be inserted and there is no space left on the associated page, we need to create a overflow page and hang it to the leaf page.
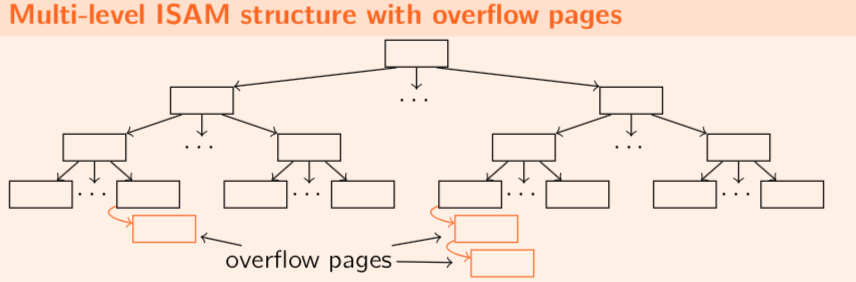
Note that records on the overflow pages are not ordered in general.
Example:
We insert the records with key 23,48,41,42.
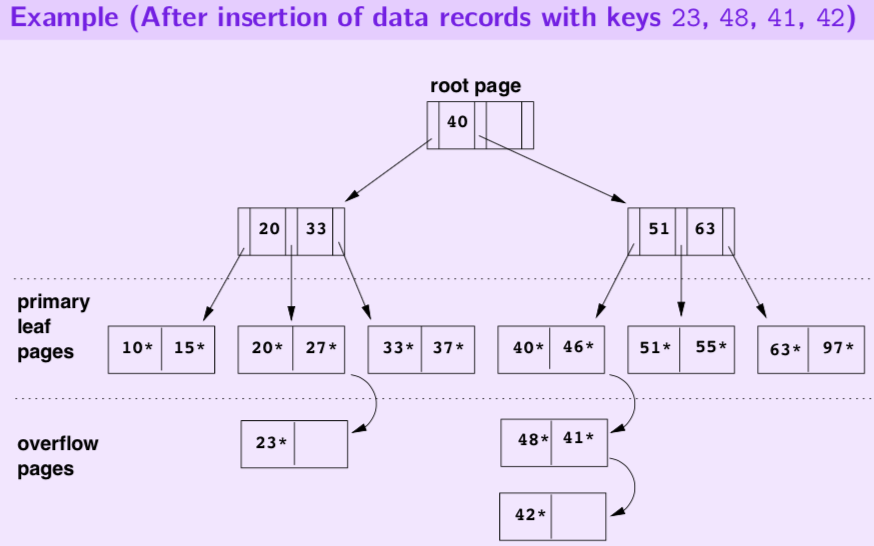
Problems of ISAM:
- Maintenance of the overflow pages is required and records in the overflow pages is not ordered. Cost is expensive.
- ISAM tree lose the balance after updating. It might lead to low performance.
- ISAM tree is static, the non-leaf levels remains the same.
B+ tree
The B+ tree is derived from the ISAM tree, but is fully dynamic with respect to updates:
- Search performance is only dependent on the height of the B+ tree.
- No overflow pages, B+ tree remains balance.
- B+ tree offers efficient insert/delete procedures, the underlying data file can grow/shrink dynamically
- B+ tree nodes(desipte the root page) are guaranteed to have a minimun occupany of 50%.
B+ tree is similar to ISAM tree, but
- the leaf nodes are connected via a double-linked list
- leaves may contain actual data records or just reference to records.(reference is the common case)
Each node of the B+ tree contains n entries, where $d \leq n \leq 2d$. The value d is a parameter of the B+ tree, called the order of the tree and is a measure of the capacity of a tree node. The root node is the only exception to this requirement on the number of entries: for the root, it is simply required that $1 \leq n \leq 2d$
Note that each node contains n+1 pointers. Pointer $p_i$( $1 \leq i \leq i$) points to a subtree in which all key value k are $k_i \leq k < k_i+1$
Example: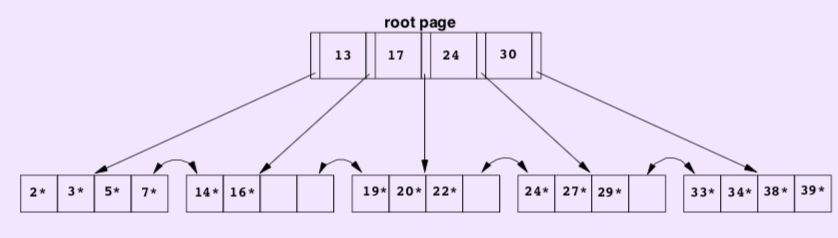
Insert
If we want to insert a record, we should:
- find the leaf page where it belongs.
- if the page has enough space, simply insert it.
- otherwise node p must be split into p and p’ and a new separator has to be inserted into the parent of p. Splitting happens recursively and may eventually lead to a split of root node.
- distribute then entries of p and the new entry
We use the above example to demonstrate the insertion process. Suppose we want to insert record with key = 8 into the B+ tree.
- The minimal key value in the root page is 13, then 8 should be inserted into the page that the left pointer of 13 points to. It’s the node with value {2,3,5,7}
- The page has no more space, it has to be split into two pages. Entries {2,3} remains on page p, entries {5,7,8} go to new page p’.
- Since we spilt a page, a new separator is also created, the value of the separator is the value of the first entry of the new page p’, here is 5.
- Insert separator into parent node. Since parent node is also full, it has to be split too. If the parent is not a root node, it splits like a normal node. If it’s a root node, it splits a little bit different.
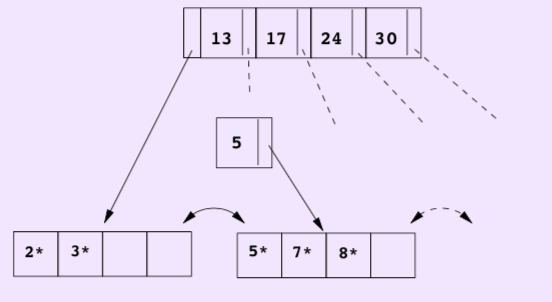
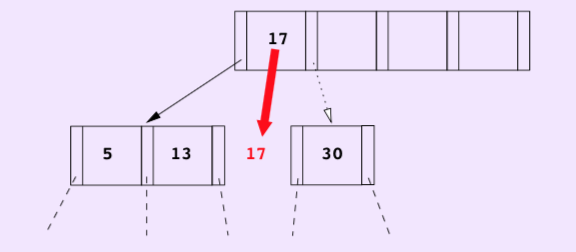
Root node split:
Now the root node should be split, if the new separator is inserted, it has {5,13,17,24,30}. We simply create a new root node which hold only the middle entry. Here entry 17 is pushed up.
Note that, splitting the old root and creating a new root node is the only situation in which the B+ tree height increase. The B+ tree remains balanced.
Delete
Deletion is the opposite to the insertion.
Here we denote $m$ the number of entries of page p and $d$ is the order of B+ tree.
To delete a record with key k
- find the page where k belongs to.
- if $m>d$, then page p has enough occupancy, simply delete k from page p.
- otherwise borrow a entry from its right(left) sibling
- If its right(left) sibling has less then $d$ entries, merging leaf nodes is required.
Example:
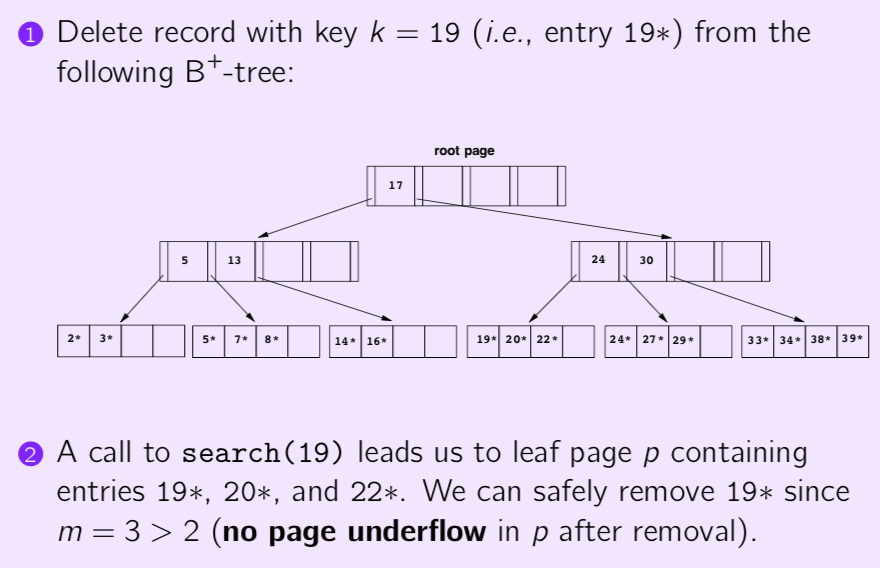
If we continue to delete entry 20
- page p is underflow(m=1 < 2=d). We now borrow an entry 24 from its right sibling p’(p’ is not underflow since it has 3 entries)
- The smallest key value(27) on page p’ is the new separator of p and p’ in their common parent.
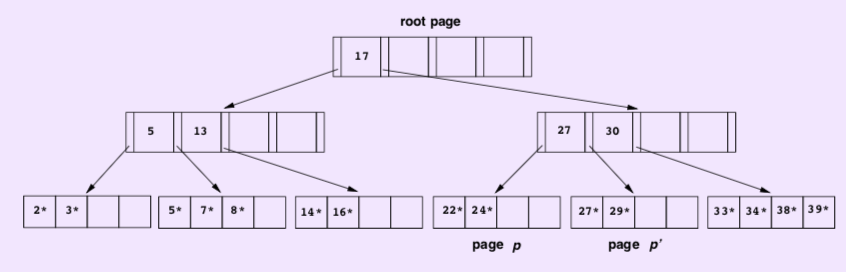
Now we continue to delete 24 from page p. We cannot borrow an entry from its sibling since its sibling is underflow. We should merge those two pages p and p’.
- Move all entries from p’ to p, then delete page p’.
- Separator 27 between p and p’ is no longer needed and thus deleted from the parent.
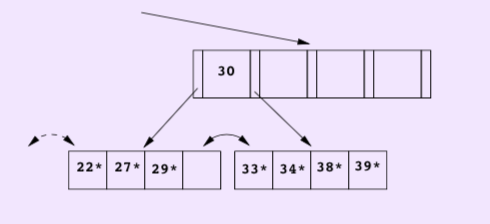
However the parent page has only one entry 30 and is thus underflow, it should borrow one entry from its left sibling, but its sibling has only d=2 entries, thus those two pages has to be merged. It leads to the merge of root node.
Root merge
We simply pull the entry in the root page down to form a new merged node. The old root node is deleted and the new merged node becomes the root node.
Finally the B+ tree looks like:
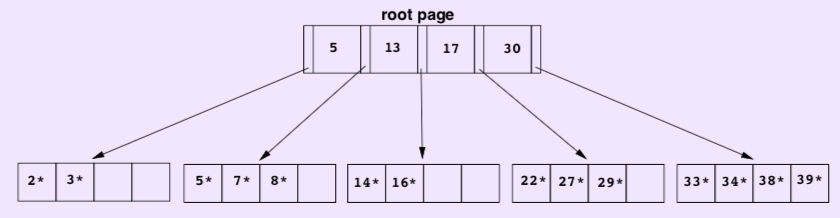
Note that this is the only situation in which the B+ tree height decreases. The B+ tree remains balanced.